
Forecasting in procurement
Lots of manual work is involved with negotiating correct and low prices. In order to do this, it is often necessary to forecast needs and spot prices. Flowtale now continue our collaboration with Maersk by developing and delivering forecasting algorithms, that are being inserted into Maersk’s procurement automation system.
Case
Maersk recently introduced us to their new procurement automation platform, which needed support from several forecasting models, which predict a variety of variables from prices to demand. Flowtale stepped in right away and in just 1 month, we developed the first estimator and delivered it as a micro-service. We did this while regularly looping in Maersk stakeholders to ensure optimal value creation and integration. The delivered estimator reached a classification cross-validation accuracy of 87% and using a simple logistic regression model and a well informed feature set. The score was an improvement from 83% by a pre-existing proof of concept script.
Procurement orders are documents that contain the expected amount of materials and services that a vessel will need at the port. These amounts must be forecasted in advance, so the procurement order can be created before arrival to the port and so the supplies and services can be ordered. Forecasting used to be done either manually by calculation in excel or using a custom software program. Nowadays, the process is becoming completely automated and integrated into the procurement system. Forecasts and estimates come from either a known formula or using statistical estimators that learn from data.
When a container ship leaves the port, invoices for supplies and services are automatically checked against the procurement order to ensure the correct amount was billed. Reasons for a mismatch can be that the need at the port did not match the pre-generated procurement order with a forecasted value or it can be that the wrong amount was delivered or billed by the supplier. In either case, every time an item in the procurement order and the invoice does not match exactly, manual work has to be done to check the correct volumes and rates.
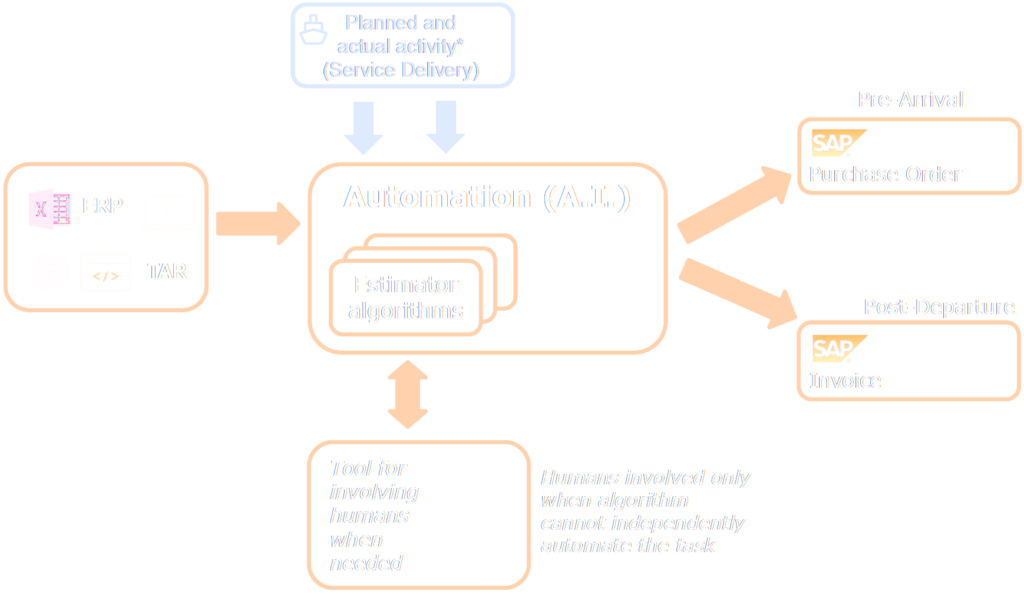
If a procurement value cannot be forecasted automatically or the value ends up not matching the invoice, that has a cost in terms of manual labor to check which value is correct and fill in the right number. The savings of an accurate automated estimator would be described by:
Savings = Number of predictions * Time * Cost/Time * Estimator accuracy
where Estimator accuracy is defined as the ratio of correct predictions per predictions overall. Time is the time it would take to update the procurement data if no prediction was available or if the prediction is not accurate, Cost/Time is the rate of labor to update procurement data and Number of predictions is the number of times an estimate is needed in the time frame where the savings are calculated. In addition to the savings from skipping manual labor in the process, estimator algorithms work quickly or even instantly. Automated algorithms are also more reliable and not subject to human error.
Simple models
When building a new forecasting model, it is easy, and somehow tempting, to throw sophisticated and flexible statistical models at the given dataset. There is much interest and hype in the industry about artificial neural networks, because they enable solving challenging and spectacular machine learning problems such as computer vision and speech translation. We often think of complicated models such as artificial neural networks as last resorts. We apply deep learning, when the problem requires a large number of features to be used and when very large training datasets are both necessary and available, such as in some computer vision, acoustic or large text processing problems. Most often, however, it is more efficient to start with the simplest models and use domain knowledge and first principles thinking to engineer informative features. Given sufficient information and rational feature engineering, simple linear or polynomial models can also reach high accuracies with the added benefit of easy interpretability and they often have better ability to extrapolate. In addition, the most simple baseline models can be developed more rapidly and deployed to production or service testing earlier.
Evaluation and iteration
Deploying products early and starting the feedback loop is generally important to avoid wasting time on unimportant features or over-engineering. The possibilities and cost/benefit of making further improvements to an estimator can be assessed and prioritized in parallel with testing the minimum viable product. Even when further improvements to a model are feasible, another forecasting problem may demand more urgent attention.
In addition, software product specification can rarely be a one-off process. It is usually iterative. Products must be integrated, tested and evaluated live in production and then optimized and adjusted. Even more so, if there is a human-machine interaction involved. The development process is most efficient when this loop is started early and iterations are small and fast. Flowtale consultants are passionate about delivering quality products that create as much value as possible. To this end we drill through layers of our clients business cases with questions. By doing this, we pose the most valuable business hypotheses and define the most valuable deliverables, in order to anticipate the optimal solution as early as possible.
Conclusion
It was possible to deliver a forecasting product quickly by following the practices of the minimal viable product approach combined with the simple estimators using domain-informed features, while deploying early and looping in the stakeholders regularly.