
TL;DR: Vision Language Models (VLMs) integrate text and image understanding, enabling AI to interpret images in a meaningful context. VLMs can answer questions about images, generate descriptions, and enhance tasks like searching for images in documents.
Introduction: The Visual AI Revolution
Artificial intelligence has come a long way in just a few years, especially when it comes to language. Large Language Models (LLMs) like GPT-4 can hold conversations, answer complex questions, and write code. But language is not the only way we use to communicate and understand the world.
That’s where multimodal AI models come into play. These models can interpret and process information from multiple sources—text, images, audio or video—allowing them to understand content across different modalities.
One of the most exciting advances in this area is the development of vision language models (VLMs), which can interpret images in the context of text and vice versa. These models go beyond simply recognizing objects in images; they can actually understand and interpret images in the context of accompanying text. For example, they can answer questions about a picture, generate descriptions of a scene, or find images that match a specific query.
In this post, we'll explore the inner workings of these multimodal models and how they differ from traditional computer vision approaches. We’ll also dive into real-world examples, including how Flowtale is leveraging vision language models for image understanding.
How Vision Language Models See Images
Conventional computer vision approaches typically focus on specific tasks like object detection, image classification, or segmentation. They are often based on convolutional neural networks trained on large datasets of labeled images. They can be highly effective for their designed tasks.
VLMs, on the other hand, are more flexible and ambitious in scope. While there are many types of VLMs, let's explore one approach that some popular multimodal LLMs are using to understand images. Keep in mind that this is likely a simplified version of the actual complex architectures used by models like GPT-4o. A typical inference process for these advanced multimodal LLMs might look something like this:
Image and Text Encoding: The model processes input images through a specialized vision encoder, transforming raw pixel data into embedding vectors that capture key visual features and patterns. If text is provided, it is first tokenized and then converted into embedding vectors using a text encoder. These embeddings serve as the foundation for the model’s understanding.
Creating a Shared Language: The model aligns the visual and textual embeddings in a shared representation space, ensuring that image-derived information is compatible with its language processing capabilities. Once this alignment occurs, the model can process image embeddings similarly to text embeddings.
Leveraging Language Understanding: The model then uses its pre-trained language capabilities to analyze, describe, or answer questions about the image. At this point, the process closely resembles standard LLM inference, where the model predicts the next tokens based on the provided input.
Generating Human-like Responses: Finally, the model generates text tokens as output, which are then decoded into human-readable responses. Because the model processes both text and images within the same representation space, it can describe visual content, answer questions about images, and generate contextually relevant text based on visual inputs.
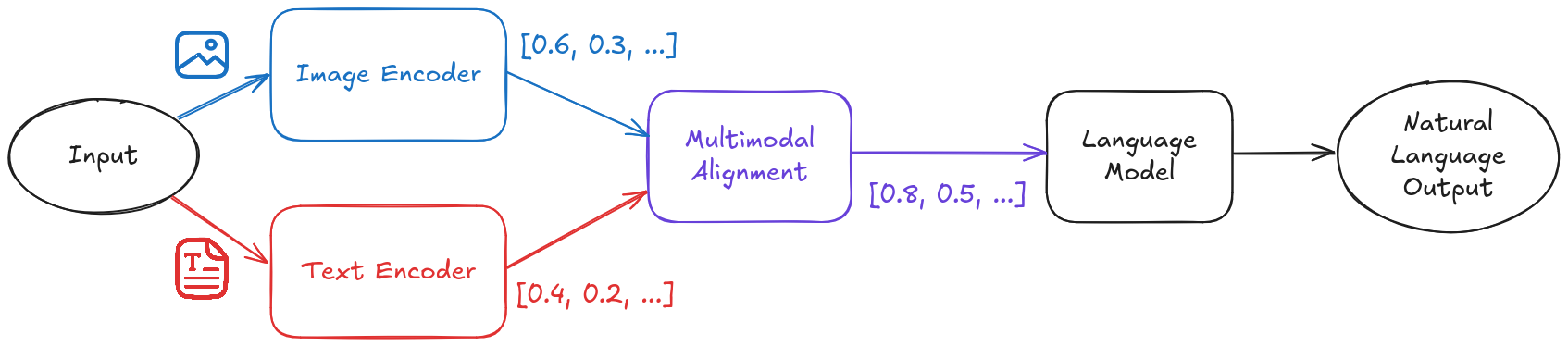
The Multimodal Alignment step may be implemented in different ways depending on the model. For example, models like LLaVA use a projection layer to map visual features into the language model’s embedding space, while others, like Flamingo, employ a perceiver resampler to process and align image representations before integrating them into the language model.
There are a few advantages of the vision language model approach compared to traditional computer vision pipelines:
| Vision Language Models | Conventional Computer Vision |
|---|---|
| Integrates vision and language understanding | Focuses on specific visual tasks |
| Can handle a wide range of vision-related tasks | Typically specialized for particular tasks |
| Provides human-readable explanations | Results may require expert interpretation |
| More adaptable to new scenarios | Often requires retraining for new tasks |
| May sacrifice precision for versatility | Can be highly precise for specific tasks |
| Generally more resource-intensive | Often more efficient for specific tasks |
Note that both approaches have their strengths, and the choice between them often depends on the specific use case. Multimodal LLMs excel at tasks requiring flexible understanding and natural language interaction, while conventional computer vision techniques remain crucial for specialized applications that require high precision or efficiency.
If you're interested in the technical side of these models, check out the paper “An Introduction to Vision-Language Modeling” – it covers how VLMs are built, trained, and evaluated.
Vision Language Models in Practice: Applications and Considerations
The potential applications of VLMs are vast and varied. Here are some ways you can start exploring their use in your business:
Enhance Customer Experience: Implement visual search or AI-powered product recommendations in e-commerce platforms.
Improve Content Management: Use AI to automatically tag and categorize images in your digital asset management system.
Boost Accessibility: Develop more accurate image description tools for visually impaired users on your websites or applications.
Streamline Document Processing: Extract text and data from images of documents, receipts, or business cards.
Enhance Social Media Monitoring: Analyze both text and images in social media posts for better brand sentiment analysis.
Case study: Flowtale's Implementation of Multimodal AI for Technical Documentation Search
We worked with a major global shipping and logistics company to transform how their engineers and technicians access technical information. The company, like many in their industry, manages vast amounts of technical documentation. Engineers and technicians need quick access to specific information across thousands of pages of manuals. Traditional keyword search methods were causing inefficiencies and potential safety risks due to missed or incomplete information.
Our initial solution was a text-based Retrieval Augmented Generation (RAG) system that enabled natural language queries, technical context understanding, and information synthesis across multiple documents. The system streamlined documentation search by providing relevant excerpts with source citations for maintenance and repair operations.
We also saw an opportunity to demonstrate how multimodal AI could further transform their information retrieval process. We developed a proof-of-concept to show how image search capabilities could enhance technical documentation search:
Semantic Image Search: We used the CLIP (Contrastive Language-Image Pre-training) model to enable searching for relevant images using natural language descriptions. This powerful capability allows users to find diagrams, schematics, or visual examples even when the search terms don't exactly match image metadata.
Natural Language Understanding: The system can interpret complex technical queries and understands the intent behind the search rather than just matching keywords.
Contextual Relevance: Retrieved images are ranked based on their semantic similarity to the query, ensuring the most relevant visual information rises to the top.
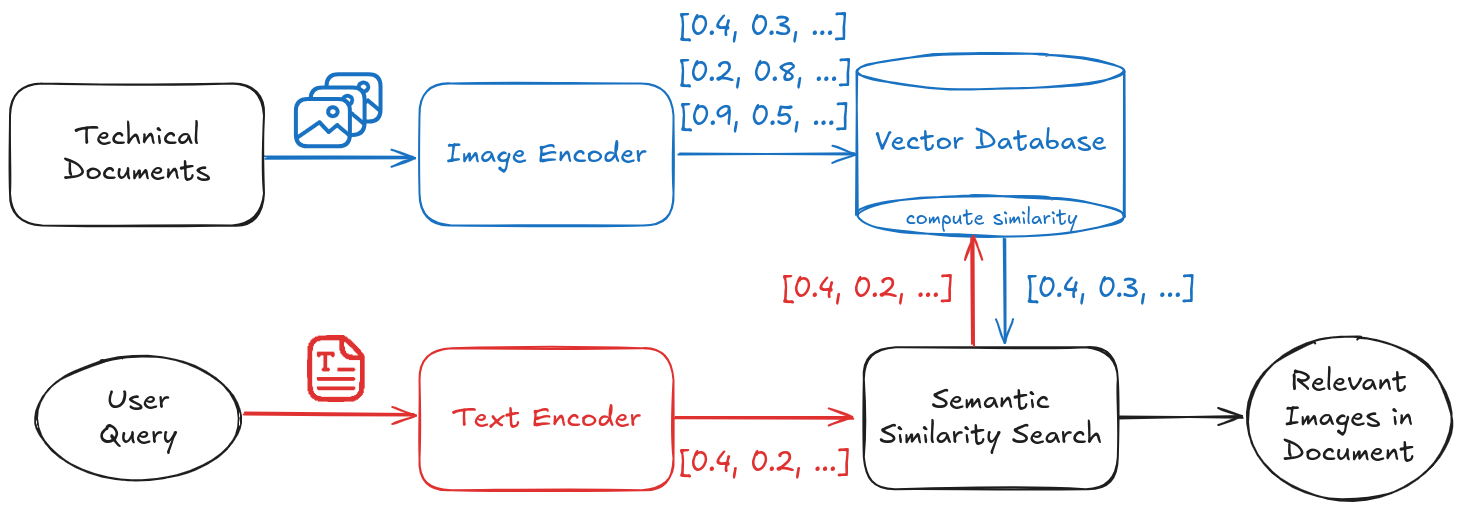
As an example, imagine a technician quickly finding a specific engine diagram by describing a component, or an engineer locating all schematics related to a particular system across multiple manuals with a single query. This capability would:
Drastically reduce time spent searching for visual information
Improve accuracy in identifying correct parts and procedures
Enhance safety by ensuring access to the most up-to-date visual references
Support training and knowledge transfer by making visual resources more accessible
Challenges and Limitations of Vision Language Models
While VLMs offer impressive capabilities in image understanding, they also come with important limitations. Users should approach their outputs carefully, especially in critical decision-making scenarios.
Here are some key limitations to keep in mind when working with VLMs:
Spatial Reasoning: VLMs often struggle with tasks requiring precise spatial understanding or localization within images.
Counting Accuracy: These models may provide approximate rather than exact counts of objects in images.
Image Orientation: Rotated or unusually shaped images can lead to misinterpretations.
Text Recognition: Small, stylized, or non-Latin scripts may pose challenges for accurate reading.
Specialized Visual Analysis: VLMs are not yet reliable for tasks like medical image interpretation or complex chart and graph analysis out-of-the-box.
Description Accuracy: Occasionally, these models might generate inaccurate descriptions, especially for complex or ambiguous scenes.
As we continue to push the boundaries of AI in visual understanding, it's important to view VLMs as powerful assistive tools rather than infallible systems. By understanding their strengths and limitations, we can leverage these models effectively while maintaining a realistic perspective on their capabilities.
Getting Started with Vision Language Models
VLMs offer groundbreaking capabilities, from advanced image understanding to multimodal data analysis. However, successfully implementing VLMs in your business requires thoughtful planning. To get started quickly and effectively, follow this step-by-step guide:
1. Prepare your data
Before using a VLM, ensure your images are:
High-quality: Clear, well-lit, and free of obstructions to improve performance.
Properly formatted: Most APIs accept PNG or JPEG files, but check documentation for specifics.
Well-organized: Maintain a structured dataset with clear filenames, metadata, or relevant categories. This helps streamline processing, especially if you later move toward fine-tuning or batch analysis.
2. Use an out-of-the-box VLM through an API for quick results
The easiest way to start with VLMs is by using a pre-built model accessible via an API. This allows you to leverage powerful vision-language capabilities without needing to train or fine-tune a model yourself.
First, we'll set up our OpenAI client with our API key:
from openai import OpenAI client = OpenAI(api_key="your_api_key_here")
Before we can send an image to the API, we need to convert it to a base64-encoded string. This is a standard format for sending binary data like images over HTTP. Here's a helper function to handle this conversion:
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "/imagespath/to/your/image.jpg"
base64_image = encode_image(image_path)
Now that we have our image encoded, we can structure our API request. The GPT-4o model accepts both text and image inputs in a specific format. We'll create a message that includes our question and the encoded image:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What do you see in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
max_tokens=300
)
print(response.choices[0].message.content)
The response will contain the model's natural language description of what it sees in the image. You can modify the prompt text and maximum number of tokens to get different types of analyses or longer responses.
3. Moving Beyond Basic API Calls
Once you’ve experimented with an out-of-the-box VLM through an API, consider these next steps for more advanced implementations:
Expand to more complex use cases: Go beyond simple image descriptions and explore applications like visual search, multimodal retrieval, or document analysis.
Implement error handling: Be prepared for cases where the model might not understand an image correctly, and design your application accordingly.
Optimize for scalability: If you’re integrating VLMs into a larger system, monitor API usage, response times, and costs. Consider caching results or using smaller models where applicable.
Selecting the Right Model for Your Needs:
For most businesses, leveraging existing models is the most efficient way to get started. When choosing a model, consider factors such as task complexity, integration needs, and budget constraints. Here are some top options with vision capabilities:
GPT-4o (Open AI): A versatile multimodal model capable of processing text, images, audio, and video. It provides state-of-the-art performance in diverse tasks, from visual question answering to audio-visual content generation, offering seamless API integration.
Gemini 1.5 Pro (Google): Natively multimodal with a groundbreaking two-million token context window. Excels in long-context tasks across text, images, audio, and video, enabling precise processing of large-scale documents, extensive codebases, and lengthy media files.
Claude 3.5 Sonnet (Anthropic): A multimodal LLM with advanced vision capabilities, excelling in visual reasoning tasks such as interpreting charts and graphs. Features a 200K token context window and shows strong performance in complex reasoning and coding tasks.
LLaVA 1.6 (Microsoft Research): An open-source model combining encoder CLIP and LLM Vicuna, perfect for research in visual question answering and image-based reasoning. Ideal for academic or experimental projects.
Qwen2-VL (Alibaba): A top-performing multimodal model, currently leading the HuggingFace OpenVLM Leaderboard among official providers. Excels in video understanding, multilingual text recognition in images, and complex visual problem-solving.
Evaluating VLMs involves benchmarking their performance across diverse tasks, such as visual reasoning, text recognition, and multimodal understanding. To explore more VLMs and compare their results on different benchmarks, check out these leaderboards:
HuggingFace OpenLLM Leaderboard
Ready to take the next step in your multimodal AI journey? At Flowtale, we're excited about the potential of multimodal AI and are here to help you navigate this rapidly evolving landscape. Reach out to us for a consultation on how we can help you harness the power of image understanding in your business.